The routing algorithm
The RouteModule is used by the server to handle requests for routes between one or more origins to one or more destinations.
As the maps are represented as directed graphs, the normal algorithm used to calculate the shortest path between two nodes is the Dijkstra algorithm. This algorithm is used in conjunction with a modified version called the A* algorithm which uses the fact that the best path ought to lie in the direction towards the destination.
The server covers a large area, hence the map database is large. For memory efficiency we have partitioned the road network into sufficiently large maps. This means that the origin and the destination are not necessarily in the same map. For calculation efficiency we introduced hierarchical maps.
As with all modules, there is a route leader and zero or more available RouteModule instances. The task of distributing sub routes is done by RouteSender object in the server.
Routing on lower hierarchical maps
If the distance between the origins and the destinations are small we have to consider all roads when calculating the best route, i.e. we are using a level 0 map. If the origin and the destination lies within the same map the algorithm calculates the route and returns the RMSubRoutes to the destination and to the external nodes that have costs that are less than the cost to the destination.
Routing to higher hierarchical maps
When routing over large distances, e.g. from Stockholm to Berlin, we cannot consider all the small roads in between, hence we have a hierarchical structure for the maps.
The difference between higher level routing and lower level routing is that the RouteModule does not route on all nodes when the route should become a higher level route. The RouteModule uses two bounding boxes to decide which nodes that should be included in the route calculation. The inner bounding box is created by taking the coordinate of the origin and expanding the box with a constant distance in the x and y directions. The outer bounding box is created the same way but with a larger increase in size. Inside the inner bounding box the following connections are allowed (higher level node means that the node exists on the overview map):
Connections from a lower level node to a lower level node.
Connections from a higher level node to a higher level node.
Connections from a lower level node to a higher level node
Inside the outer bounding box the following connections are allowed:
Connections from a lower level node to a higher level node.
Connections from a higher level node to a higher level node.
This decreases the number of nodes and connections that have to be considered by the Dijkstra algorithm, hopefully without decreasing the optimality of the route very much.
Calculating the cost
To quickly reach the destination we will use an algorithm that attracts the route towards the destination node, i.e. the A* algorithm. This is done by adding a second cost that represents the estimated cost of getting from the origin to the destination. This cost is used to decide which node to remove from the heap. When we update a node we first calculate the cost of getting from the origin to the current node and store this value in the normal cost. Then an estimation of the distance from the current node to the closest destination will be calculated and added to the estimation cost. This cost has to be lower than the actual cost to guarantee an optimal path. If we are using distance as cost parameter we would like to use the flight distance as the estimation. This is an expensive calculation, but it seems that the cost of reading/writing nodes from memory greatly overshadows this problem, so the estimated distance is calculated as sqrt( deltax2 + deltay2 ). If the cost represents time we use dist/max(speed) for the estimation. Currently max(speed) is set to 120 km/h.
CalRoute
For each RoutingMap loaded in the RouteModule, a CalcRoute object is created. The RoutingMap is deleted when the CalcRoute is deleted. CalcRoute is the class that does the actual routing.
Member functions
route Main function that loops through functions below for each request.
removeDups Removes identical origins and destinations.
routeOnOneSegment Creates routes where the origin and destination is on the same segment.
initRoute Prepares the map and queues for the Dijkstra algorithm.
calcCostDijkstra This function uses the Dijkstra algorithm or the A* algorithm to create routes to the destination nodes.
calcCostExternalDijkstra Calculates routes from the origin to all external connections.
readResult Reads the routes from external nodes and/or destinations back to origins.
removeDups
This method removes duplicate origins and duplicate destinations. This is necessary for e.g. calcCostDijkstra which ends when all destinations are found.
routeOnOneSegment
The method routeOnOneSegment is called before initRoute and loops over all origins and destinations and checks if the node id is the same for the current origin and destination. If the node id is the same, it calculates a route on the segment if the offset for the destination is greater than the offset for the origin. The RouteModule uses offset from the current node (unlike the rest of MC2 that always uses offset from node zero) which makes calculations easier to follow. The one segment routes created by the method are put into the result list and then it is up to the server to decide whether to use it or not. State changes and penalties are added to the route if it is impossible to drive on the segment.
initRoute and initRouteFirstTime
The method initRoute enqueues the start nodes into the priority queue. If the originalRequest-flag is set in the packet from the server, initRouteFirstTime is called instead. This behaviour should change, since there can be both first time-routes and continued routes in the same request from the server. initRouteFirstTime takes the offset into consideration and does not enqueue the start nodes themselves, but takes the origins and enqueues the nodes to which the origins have connections. The offset cost of the origin nodes are subtracted from the cost of the enqueued nodes. initRouteFirstTime also enqueues nodes with restrictions which make the nodes forbidden for the vehicle selected by the user. These are enqueued in a separate queue, m_notValidPriorityQueue. If there are no valid nodes in the ordinary priority queue, the nodes in m_notValidPriorityQueue will be expanded until a valid node is reached. This node is then inserted into the normal priority queue and the ordinary routing can begin.
calcCostDijkstra} and calcCostExternalDijkstra
These two methods do essentially the same thing, i.e. calculates the shortest path from the origin to the destination(s) using the Dijkstra algorithm. The difference it that calcCostDijkstra stops after finding one or many destinations (depending on the input) or until the heap is empty and calcCostExternalDijkstra runs until the heap is empty. The methods dequeue nodes from the priority queue. Every connection from the dequeued node is checked for vehicle restrictions and every connected node is checked for node restrictions. If the connection and new node have restrictions which are allowed, the real cost and estimated cost of the new node are updated with the connection costs and, if the cost is less than the cut off, it is enqueued into the priority queue. The gradient of the new node is set to the old node so that the route can be followed backwards from the destination when the result is read. This is repeated until the stop criteria for the function is fulfilled.
readResult
After the Dijkstra functions are run readResult is called. The main task for the method is to create RMSubRoutes by following the gradients of the destination nodes back to the origins. But before this can be done it has to check if the destination could be reached the normal way or not. calcCostDijkstra and calcCostExternalDijkstra only consider the nodes that can be reached using the vehicle selected by the user. Sometimes that vehicle is not allowed to be used all the way to the destination. If this is the case we try to calculate the last part of the route using a pedestrian as vehicle. It is done like this:
The destinations are checked. If no destinations have been reached with the normal vehicle we continue to the next step.
The estimated cost of the destination nodes are set to
0.The destination nodes are equeued into the
m_notValidPriorityQueue.Routes are made from the destinations using
m_notValidPriorityQueueand backward routing, but only the estimated cost of the nodes are used (in the methodexpandNonValidNodesResult).If a node with the real cost set (by
calcCostDijkstra) is reached it is put intom_normal-PriorityQueue.All the nodes affected by
expandNonValidNodesResultexcept the ones inm_normal-PriorityQueueare reset to default values.expandNodesResultis run. It calculates forward routes from the nodes inm_normal-PriorityQueueto the destination without considering vehicle restrictions.
When this is done readResulFromDestination is called for all destinations that were reached and the RMSubRoutes are created. These are then sent to the server.
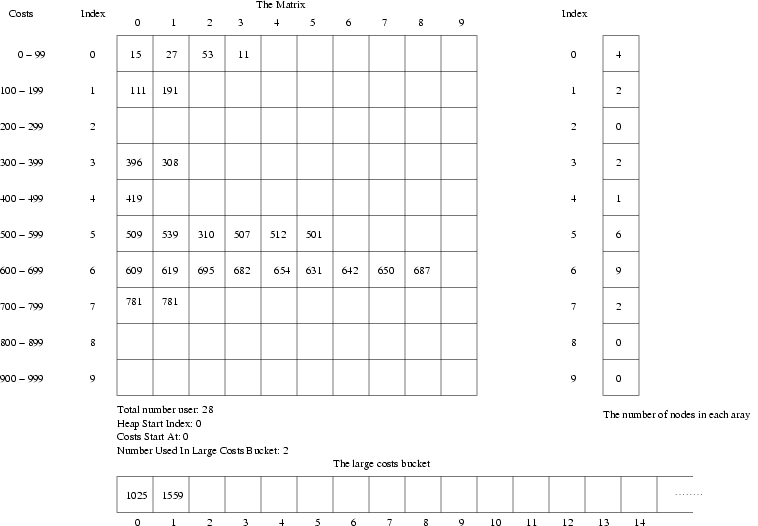
The BucketHeap
The BucketHeap is the heap type used by the Dijkstra algorithm in the RouteModule.
The idea of the heap
The BucketHeap is a data structure specifically designed to be used as a heap in the Dijkstra algorithm. Its idea is that the heap consists of several buckets in which to put nodes of the graphs (=maps). A specific range of costs has been assigned to each bucket so that each bucket contains nodes with about the same cost. In a bucket, the ordering of the nodes is not important, and therefore nodes can be inserted into the heap very fast. The only thing to be done is finding the correct bucket. Removing a node from a bucket is somewhat more slow, the bucket containing the nodes with the least cost has to be searched for the minimum cost with linear search, which is slow. To improve the speed of the heap, no sorting should be done unless there is a destination node in the current bucket.
Algorithms for the BucketHeap
The only supported operations on the BucketHeap are enqueue, dequeue, isEmpty and reset. The reason that no other operations are defined is that the kind of Dijkstra used does only need these. The heap work in the following way:
The buckets of the heaps all carry nodes with ascending costs, i.e. one bucket contains nodes carrying the currently lowest costs, the next bucket contains the following node costs and so on. The cost span is the same for all buckets. The bucket with the lowest costs, the minimum cost bucket, and the lowest cost available for enqueue itself are stored in variables. The maximum cost is decided by the number of buckets and the cost span of a bucket. This implies that only a finite cost range of node costs can exist at a time in the heaps. However, the Dijkstra algorithm will never enqueue a node with cost lower than the lowest cost the heap can handle (that node cannot have been previously dequeued). If, for any reason, this happens anyway, the node will be enqueued in the minimum costs bucket and will be found. If a node with larger cost is to be enqueued, it will simply have to be put into a special, extra large bucket that is used for too large costs, the large costs bucket.
As the buckets have a finite size, overflow might occur. Therefore, to every bucket (also the large costs bucket) an overflow list is attached to take care of the overflow nodes. Normally, these lists will be empty.
Resetting
The reset operation simply marks the buckets as empty and sets all other variables (like the minimum cost the heap is supposed to handle and the bucket with the minimum cost) to zero or something equivalent. If overflow has occurred during the routing, the overflow lists will be cleared.
Enqueueing a node
There are three cases that can occur when starting enqueue. If the cost of the node is so large that it is larger than the cost span of the heap the node has to be put into the large costs bucket. This very large bucket should be emptied by dequeue at certain conditions. If the cost is smaller than what the minimum cost bucket holds, the node will be enqueued into that bucket anyway. This will not pose a problem, since dequeue will find that node in its linear search and return it. Although the approach with too small costs is straightforward it should never happen, as Dijkstra and Dijkstra-like algorithms never will enqueue a node with smaller cost than the lowest cost in the heap. There are some special cases though, when a modified algorithm makes this happen. The third and most common case of costs is when the cost of a node fits into the cost span. The correct bucket to put the node into is computed, and the node is enqueued. Also, a variable containing the total number of nodes is increased.
If the chosen bucket is full when one wants to put more nodes in it, overflows, the node will be put in the respective overflow list by a special function overflowEnqueue.
Checking if the heap is empty
The operation isEmpty is the simplest. It simply checks if all buckets are empty. If so is the case, the function returns true, otherwise false. This will be done by checking if the total number of nodes is zero.
Dequeuing the minimum cost node
The dequeue-operation is the most time consuming and complex of the BucketHeap, because all work has been left to this function. First a consolidating function, flushHeap is called. It examines the minimum cost bucket and if the number of nodes in this bucket is zero, the next bucket in cost order becomes the minimum cost bucket and the old bucket is assigned costs one step higher than the previously largest costs. If the first bucket that was the minimum cost bucket has again become minimum cost bucket flushHeap calls another function, tryToEmptyLargeCostsBucket, that will try to empty the large costs bucket carrying the nodes that previously had too large costs to be enqueued into the normal buckets. There is a good chance that many of the nodes in this bucket now successfully can be moved to the normal heap, because the node costs handled by the heap now are substantially larger. The reason for moving the nodes back to the normal heap is that dequeuing never will take place in the large costs bucket. The function tryToEmptyLargeCostsBucket examines every element in the large costs bucket and, if the current node is enqueueable, puts it into the right bucket, just as enqueue would. If the node still has a too large cost it will remain in the large costs bucket. When tryToEmptyLargeCostsBucket and flushHeap are done, dequeue has a minimum cost bucket containing nodes and starts to search (with linear search) for the node with the smallest cost. When that node is found the total number of nodes in the heap is decreased and the minimum cost node is returned. If this bucket has a non-empty overflow list the function overflowDequeue will browse the list and the minimum cost bucket to find the minimum cost node.
Implementation of the heap
The buckets are implemented as a matrix with the rows as buckets and the columns representing spaces in the buckets. The large costs bucket is an extra large array (if the length of a bucket array is $A$, the length of the large costs bucket has length A*, just to make sure that it is so large that overflow almost never occurs). The number of nodes in a bucket is stored as an array with the size of the number of rows in the matrix. Thus, when performing reset only the array is set to zero, and the time consuming reset of the heap matrix is omitted. The number of nodes in the heap is stored in a variable and then isEmpty only needs to check if this variable is zero or not.
When enqueue decides which bucket (row in the matrix) a node should be put into the following piece of code is used:
rowIndex = ((cost - m_costsStartAt) >>
MATRIX_DIFF_EXPONENTIAL) + m_heapStartIndex;
while (rowIndex >= ROWS)
rowIndex -= ROWS;Here rowIndex denotes the row chosen, cost is the cost of the node to enqueue, m_costsStartAt is the lower cost bound of the heap and m_heapStartIndex is the index of the matrix that denotes the minimum cost bucket. ROWS is the number of rows in the matrix (number of buckets). The MATRIX_DIFF is the cost span of a bucket which equals 2MATRIX_DIFF_EXPONENTIAL. The logical shift operation >> is used instead of dividing, as this is an essentially faster operation.
The four important heap constants are ROWS (= the number of buckets), COLUMNS (= the number of possible spaces to put a node into in each bucket), MATRIX_DIFF (= the cost difference between two rows in the matrix, i.e. between two buckets) and MATRIX_DIFF_EXPONENTIAL which was explained above. These parameters have an enormous influence on the performance of the Bucket Heap and the choice of these constants is a matter of optimization. See figure below for an example of the BucketHeap.
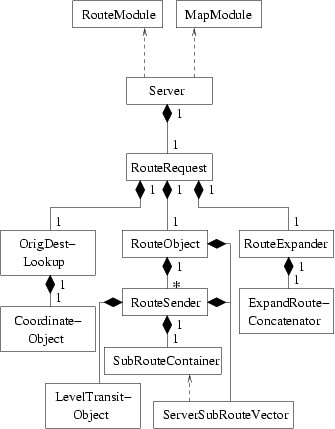
RouteRequest and subclasses
The tree of classes under RouteRequest takes care of the intelligence that controls how to do routing between maps, whereas the RouteModule does the routing on each map. These two instances communicate through the classes held in ServersShared described in a separate section below. Dependencies within the server as well as to the shared objects are found in this figure.
CoordinateObject
This class handles questions concerning mapping from coordinates to item. It finds the item closest to the coordinate. Note that two maps can overlap, and hence several maps may contain the required information.
Member functions
processPacket Takes care of a
CoordinateReplyPacketafter a request has been sent, and either generates a new request or prepares the answer.getNextPacket Returns the next packet from
m_packetsReadyToSendaddCoordinate Adds a coordinate to the question.
getCoordinateReply Returns a
CoordinateReplyPacketas an answer to the original question.
OrigDestLookup
This class is used to complete data about each OrigDestInfo in a request, and uses a CoordinateObject for one type of questions.
Member functions
processPacket Takes care of a
CoordinateReplyPacketor anItemReplyPacketafter a request has been sent.getNextPacket Returns the next packet from
m_outgoingQueue.
ServerSubRouteVector
Inheriting from Shared class SubRouteVector this class will help other server classes to keep track of what SubRoutes have been routed on and which to continue.
Member functions
insertSubRoute Inserts an element last in the vector. Also tells the SubRoute what index it is.
getCutOff Returns the greatest of the costs to get to a destination if we should return the routes to all destinations. Returns the cheapest cost to one destination if this is the last part of the route. MAX_UINT32 if we have not reached all destinations yet.
containsCheaperThan Returns true if the vector contains a subroute with cheaper or same real cost to the same destination node.
merge Adds all the SubRoutes from sourceVector, except the last one, which instead is returned.
getResultVector Function for finding the SubRoutes that make up a route with specified index to
m_destIndexArraywhen routing is finished.
SubRouteContainer
Main server class for holding information about a group of SubRoutes while routing. When routing is finished, the SubRoutes will instead be put in a ServerSubRouteVector.
Entries consist of SubRoutePair objects (see pair in map in STL). Key is estimated cost in the node where the SubRoute ends. By using this key, two things will go faster:
Assigning a new best SubRoute when the previous is dequeued.
Finding and removing SubRoutes above cutoff cost.
Data in the pair is a pointer to a SubRoute. Class inherits from multimap (STL).
Member functions
moveAllSubRoutes Finds and dequeues all remaining SubRoutes in the container and moves them to specified resultVector.
dequeueSubRoutesFromBestMap Finds and dequeues all
SubRoutesending inm_mapIDBestSubRoute.checkAndInsertSubRoute Uses multimap function ‘insert’ on a
SubRoutepointer.insertSubRoute Uses multimap function ‘insert’ on a SubRoute pointer.
insertOrigDestInfo Inserts an
OrigDestInfoas a newSubRouteinto the container.updateContainer Calls
clearGreaterThanCutOffand then updatesm_mapIDBestSubRoute.updateCutOff Sets the value of
m_cutOffif new cutOff smaller thanm_cutOff.getSize Returns the size of the
SubRouteContainer
LevelTransitObject
This class does all the tasks involved in going up and down a level in the routing. That includes finding origin and destination nodes on higher level, and keeping track of which maps to route on after routing on higher level.
Member functions
processPacket Takes care of a range of different
ReplyPackets after a request has been sent, and either generates a new request or prepares an answer.getNextPacket Returns the next packet from
m_outgoingQueue.allowedMapID Returns true if specified mapID is in
m_destMapSet.getLowerLevelDest Returns an OrigDestInfo from
m_matchHighLowIDMapspecified by map ID and node ID.getHigherLevelOrigList Returns
m_higherLevelOrigListwhich must previously have been created by this object.getHigherLevelDestList Returns
m_higherLevelDestListwhich must previously have been created by this object.
RouteSender
Adminstrates the packets for a route request. Divides the question into subroute requests for a single map, and then creates a RequestPacket for that question. The packet is sent through the server to the RouteModule to be calculated.
Member functions
processPacket Takes care of a range of different
ReplyPacketpackets after a request has been sent, and either generates a new request or prepares an answer.getNextPacket Returns the next packet from
m_outgoingQueue.getRoute Goes through the
m_finishedSubRouteVectorand backtracks the finished routes. Each of these is aSubRouteVector. Return type isSubRouteVectorVector.insertOrigDestInfo Inserts an origin as destination in a SubRoute to initialize routing there. Then adds this SubRoute to
m_requestSubRouteContainer.
RouteObject
Class for taking care of a route. Any number of origins and destinations can be used but in most cases only one origin and one destination is used or either multiple origin or multiple destinations but not both.
Member functions
processPacket Takes care of a range of different
ReplyPacketpackets and rebuilds the outgoing list.getNextPacket Returns the next packet from
getNextPacketinm_routeSender.getRoute Returns the answer to the constructor question when the routing is finished.
ExpandRouteConcatenator
Creates a new list of split packets internally in the object.
RouteExpander
Class that creates an expanded list of directions corresponding to a finished route.
Member functions
processPacket Takes care of a
ExpandRouteReplyPacketand merges all to one route.getNextPacket Returns the next
ExpandRouteRequestPacketpackets fromm_requestPacketList.getList Returns the answer to the constructor question when the routing is finished.
RouteRequest
This class administrates a routing question.
Member functions
processPacket Takes care of a
ReplyPacketand sends on to the appropriate child.getNextPacket Returns the next
RequestPacketfrom the appropriate child.getExpandedRoute Get the route as an
ExpandedRouteobject that is easy to use.addOrigin Adds an origin for the routing. Must be called before the
RouteRequestis processed.addDestination Adds a destination for the routing. Must be called before the
RouteRequestis processed.getStatus The status after the
RouteRequesthas been processed. StringTable::OK if routing was successful.